Learn Python by Building 10 Apps
user_input = input("Prompt: ")
if / else statements
if condition and condition or condition:
do some things
elif conidtion or condition:
do some things
else:
do some things
while loops
while True:
do some things
name = 'Wes'
print("Hello {}".format(name))
print(f"Hello {name}")
print(f'Hello {name}')
functions
def my_function():
do some things
return new_thing
App3 - birthday
dates
import datetime
today = datetime.date.today()
# date = datetime.date(year, month, day)
May_1_2018 = datetime.date(2018, 5, 1)
days_difference = today.day - May_1_2018.day
times
timespans
App4
multiple files / modules
file i/o
import os
filename = os.path.abspath(os.path.join('.', 'journals', name + '.jrl'))
if os.path.exists(filename):
with open(filename) as fin:
for entry in fin.readlines():
do some things
with open(filename, 'w') as fout:
for entry in journal_data:
fout.write(entry + '\n')
os independent path management
filename = os.path.abspath(os.path.join('.', 'journals', name + '.jrl'))
for-in loops
iterators
_ _name_ _
if __name__ == '__main__':
main()
doc strings
def load(name):
"""
This method creates and loads a new journal.
:param name: The base name of the journal to load.
:return: A new journal data structure populated with the file data.
"""
App5
screen scraping
import requests
import bs4
url = 'https://www.wunderground.com/weather-forecast/72202'
# get page
response = requests.get(url)
# parse html (reponse.text) into DOM
soup = bs4.BeautifulSoup(response.text, 'html.parser')
# get location, condition, temp, scale (F vs C)
loc = soup.find(class_='region-content-header').find('h1').get_text()
condition = soup.find(class_='condition-icon').get_text()
temp = soup.find(class_='wu-unit-temperature').find(
class_='wu-value').get_text()
scale = soup.find(class_='wu-unit-temperature').find(
class_='wu-label').get_text()
http requests
import requests
url = 'https://www.wunderground.com/weather-forecast/72202'
response = requests.get(url)
virtual environments
tuples and named tuples
m = (22.5, 44.234, 19.02, 'strong')
temp = m[0]
quality = m[3]
m = 22.5, 44.234, 19.02, 'strong'
print(m) # (22.5, 44.234, 19.02, 'strong')
t, la, lo, q = m
# t=22.5, la=44.234, lo=19.02, q='strong'
import collections
WeatherReport = collections.namedtuple(
'Measurement',
'temp, lat, long, quality')
m = Measurement(22.5, 44.234, 19.02, 'strong')
temp = m[0]
temp = m.temp
quality = m.quality
print(m)
# Measurement(temp=22.5, lat=44.234, long=19.02, quality='strong')
beautiful soup package
import bs4
soup = bs4.BeautifulSoup(reponse.text, 'html.parser')
slicing
nums = [2, 3, 5, 6, 11, 13, 17, 19, 23]
first_prime = nums[0] # 2
last_prime = nums[-1] # 23
lowest_four = nums[0:4] # [2, 3, 5, 7]
lowest_four = nums[:4] # [2, 3, 5, 7]
Middle = nums[3:6] # [7, 11, 13]
last_four = nums[5:9] # [13, 17, 19, 23]
last_four = nums[5:] # [13, 17, 19, 23]
last_four = nums[-4:] # [13, 17, 19, 23]
App6
http clients (binary data)
import os
import shutil
import requests
def get_cat(folder, name):
url = 'http://consuming-python-services-api.azurewebsites.net/cats/random'
data = get_data_from_url(url)
save_image(folder, name, data)
def get_data_from_url(url):
response = requests.get(url, stream=True)
return response.raw
def save_image(folder, name, data):
file_name = os.path.join(folder, name + '.jpg')
with open(file_name, 'wb') as fout:
shutil.copyfileobj(data, fout)
import platform
if platform.system() == 'Darwin':
subprocess.call(['open', folder])
elif platform.system() == 'Windows':
subprocess.call(['explorer', folder])
elif platform.system() == 'Linux':
subprocess.call(['xdg-open', folder])
else:
print("We don't support your os: " + platform.system())
App 7
classes
class Creature:
# initializer
def __init__(self, name, level):
self.name = name
self.level = level
def __repr__(self):
return "Creature {} of level {}".format(
self.name, self.level
)
def walk(self):
print('{} walks around'.format(self.name))
inheritance
class Dragon(Creature):
def __init__(self, name, level, scale_thickness):
super().__init__(name, level) # initializer for Creature
self.scale_thickness = scale_thickness
def breath_fire(): ...
duck typing and polymorphism
# all types derive from Creature
creatures = [
SmallAnimal('Toad', 1),
Creature('Tiger', 12),
SmallAnimal('Bat', 3),
Dragon('Dragon', 50, 75),
Wizard('Evil Wizard', 1000)
]
wiard = Wizard('Gandolf', 22)
for c in creatures:
wizard.attack(c)
# Wizard knows how to battle any type of Creature
# Duck Typing
# "If it looks/acts like a Duck -- it's a duck"
# wizard.attack(c) in most languages would require 'c'
# to have inherited from Creature, given that .attack()
# takes a creature. Python's Duck Typing takes
# 'things that look like creatures'
App8
generator methods
# yield makes fibonacci a generator method
def fibonacci(limit):
current = 0
next = 1
# after item is returned and processed,
# execution returns and resumes
while current < limit:
current, next = next, next + current
yield current
# yield keyword returns one element of a sequence
yield from
def search_folders(folder, text):
# for macOS if .DS_Store error
# glob.glob(os.path.join(folder, '*'))
items = os.listdir(folder)
for item in items:
full_item = os.path.join(folder, item)
if os.path.isdir(full_item):
yield from search_folders(full_item, text)
else:
yield from search_file(full_item, text)
def search_file(filename, search_text):
# matches = []
with open(filename, 'r', encoding='utf-8') as fin:
line_num = 0
for line in fin:
line_num += 1
if line.lower().find(search_text) >= 0:
m = SearchResult(line=line_num, file=filename, text=line)
yield m
recursion
def factorial(n):
# base case - break out of loop
if n <= 1:
return 1
return n * factorial(n - 1)
App9
dictionaries
info = dict()
info['age'] = 42
info['loc'] = 'Italy'
info = dict(age=42, loc='Italy')
info = {'age': 42, 'loc': 'Italy'}
location = info['loc']
if 'age' in info: # test for key
# use info['age']
lambda methods
def find_sig_nums(nums, predicate):
for n in nums:
if predicate(n):
yield n
number = [1, 1, 2, 3, 5, 8, 21, 34]
sig = find_sig_nums(numbers, lambda x: x % 2 == 1)
# sig -> [1, 1, 3, 5, 13, 21]
class Purchase:
def __init__(self, street, city, zipcode, state, beds, baths, sq__ft,
home_type, sale_date, price, latitude, longitude):
self.longitude = longitude
self.latitude = latitude
self.price = price
self.sale_date = sale_date
self.type = home_type
self.sq__ft = sq__ft
self.baths = baths
self.beds = beds
self.state = state
self.zip = zipcode
self.city = city
self.street = street
@staticmethod
def create_from_dict(lookup):
return Purchase(
lookup['street'],
lookup['city'],
lookup['zip'],
lookup['state'],
int(lookup['beds']),
int(lookup['baths']),
int(lookup['sq__ft']),
lookup['type'],
lookup['sale_date'],
float(lookup['price']),
float(lookup['latitude']),
float(lookup['longitude'])
)
def load_file(filename):
with open(filename, 'r', encoding='utf-8') as fin:
reader = csv.DictReader(fin)
purchases = []
for row in reader:
p = Purchase.create_from_dict(row)
purchases.append(p)
return purchases
coding for python 3 and 2
try:
import statistics # only Python 3.4.3+
except:
import statistics_2_stand_in as statistics
numbers = [1, 6, 99, ..., 5]
the_avg = statistics.mean(numbers)
# statistics_2_stand_in.py
def mean(lst):
# your implementation of mean here...
return avg
list comprehensions
paying_usernames = [
u.name # projection
for u in get_active_customers() # source
if u.last_purchase == today # filter
]
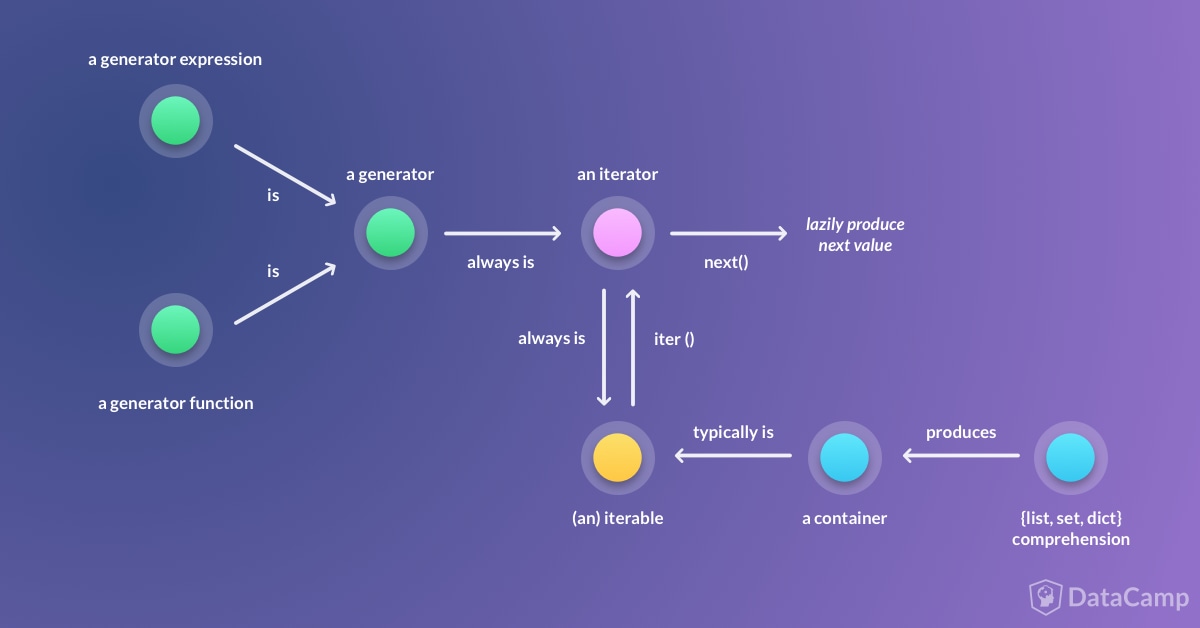
generator expressions
# works like generator methods / yield
paying_usernames = (
u.name
for u in get_active_customers()
if u.last_purchase == today
)
# You can not index into generators
data pipelines
all_transactions = get_tx_stream()
interesting_tx = (
tx
for tx in all_transactions # calls transaction stream
if is_interesting(tx)
)
potentially_sellable_tx = (
tx
for tx in interesting_tx # calls above
if is_sellable(tx)
)
nearby_sellable_interesting_tx = (
tx
for tx in potentially_sellable_tx # calls above
if is_nearby(tx)
)
App10
error and exception handling
if not search_text or not search_text.strip():
raise ValueError("Search text is required.")
try / except
try:
method1()
method2()
method3()
except ConnectionError as ce:
# handle network error
except Exception as x:
# handle general error
handling errors by type
try:
search = input("Movie search text (x to exit): ")
if search != 'x':
results = movie_svc.find_movies(search)
print("Found {} results.".format(len(results)))
for r in results:
print("{} -- {}".format(
r.year, r.title
))
print()
# Order from more specfic to more general
except ValueError:
print("Error: Search text is required.")
except requests.exceptions.ConnectionError:
print("Error: Your network is down.")
except Exception as x:
print("Unexpected error. Details: {}".format(x))
raising errors
def find_movies(search_text):
if not search_text or not search_text.strip():
raise ValueError("Search text is required.")
# raise will immediately return from function with error